Google cập nhật Mô hình AI Gemini chạy nhanh hơn, có cửa sổ ngữ cảnh dài hơn và thêm tác nhân AI
Sự kiện thường niên Google I/O 2024 của Google tại Mountain View (bang California, Mỹ) diễn ra trong 2 ngày 14 và 15-5-2024 (tức 15 và 16-5-2024 theo giờ VN). Google I/O (Google Input/Output) hằng năm là nơi Google giới thiệu với cộng đồng thế giới các công nghệ và sản phẩm mới nhất của mình. Năm 2024 này, đây là sự kiện I/O của trí tuệ nhân tạo (AI), đánh dấu kỷ nguyên Gemini AI của Google và giới thiệu với cộng đồng người dùng Android toàn cầu phiên bản hệ điều hành di động Android 15.

Ông Demis Hassabis, CEO Google DeepMind, tại buổi khai mạc Google I/O 2024. (Ảnh do Google cung cấp).
Trong buổi khai mạc, ông Demis Hassabis, CEO Google DeepMind, đại diện đội ngũ Gemini, đã giới thiệu với người tham dự trực tiếp tại giảng đường Shoreline Amphitheatre (Mountain View, California) và được Live toàn cầu, những cập nhật mới nhất cũng như sắp tới của Gemini. Đây là một mô hình AI năng lực nhất cho đến nay của Google, có khả năng đa phương thức một cách tự nhiên (natively multimodal), suy luận xuyên suốt trên các định dạng văn bản, hình ảnh, video, code và hơn thế nữa.

Ông Sundar Pichai, CEO của Google, trong bài keynote khai mạc Google I/O 2024. (Ảnh do Google cung cấp).
Ông Sundar Pichai, CEO của Google, trong bài keynote khai mạc Google I/O 2024 đã nhấn mạnh: Google đang hoàn toàn bước vào kỷ nguyên Gemini. Và cho biết: Hiện nay, tất cả các sản phẩm phục vụ 2 tỷ người dùng của Google đều tích hợp Gemini.

Ông Demis Hassabis. (Ảnh do Google cung cấp).
Ông Demis Hassabis thông báo: “Chúng tôi mang đến một loạt cập nhật trên các mô hình Gemini, bao gồm phiên bản 1.5 Flash mới, mô hình tùy biến nhẹ hơn nhằm ưu tiên tốc độ và hiệu quả; cùng với dự án Project Astra, minh chứng cho tầm nhìn của chúng tôi về tương lai của trợ lý AI (AI assistants).”
Vào tháng 12-2023, Google đã ra mắt mô hình AI đa phương thức (natively multimodal model) đầu tiên là Gemini 1.0, với 3 phiên bản: Ultra, Pro và Nano. Chỉ vài tháng sau, Google đã phát hành mô hình 1.5 Pro, với hiệu năng nâng cao và hỗ trợ cửa sổ ngữ cảnh dài (long context window) mang tính đột phá với 1 triệu mã token. (Token là đơn vị cơ bản của văn bản mà mô hình hiểu được trong mô hình ngôn ngữ lớn LLM).
Theo ông Demis Hassabis, các nhà phát triển và khách hàng doanh nghiệp đã sử dụng Gemini 1.5 Pro theo những cách đáng kinh ngạc và nhận thấy mô hình này vô cùng hữu ích nhờ cửa sổ ngữ cảnh dài, các khả năng lý luận đa phương thức (multimodal reasoning capabilities) và hiệu năng tổng thể ấn tượng.
Từ phản hồi của người dùng, Google đã ghi nhận một số ứng dụng cần độ trễ và chi phí vận hành thấp hơn. Vì vậy ngày 14-5-2024, ngay trong dịo Google I/O 2024, Google đã giới thiệu Gemini 1.5 Flash: mô hình nhẹ hơn 1.5 Pro, được thiết kế tập trung vào tốc độ và hiệu quả hoạt động trên quy mô lớn.
Cả 1.5 Pro và 1.5 Flash đều có sẵn ở bản xem trước công khai với cửa sổ ngữ cảnh 1 triệu mã token trên Google AI Studio và Vertex AI. Cửa sổ ngữ cảnh 2 triệu mã token có sẵn cho các nhà phát triển và khách hàng Google Cloud trong danh sách chờ.
Ông Demis Hassabis cũng công bố thế hệ mô hình AI mã nguồn mở tiếp theo, Gemma 2, và chia sẻ sơ qua về Dự án Astra (Project Astra).
Thông tin cập nhật về các mô hình Gemini
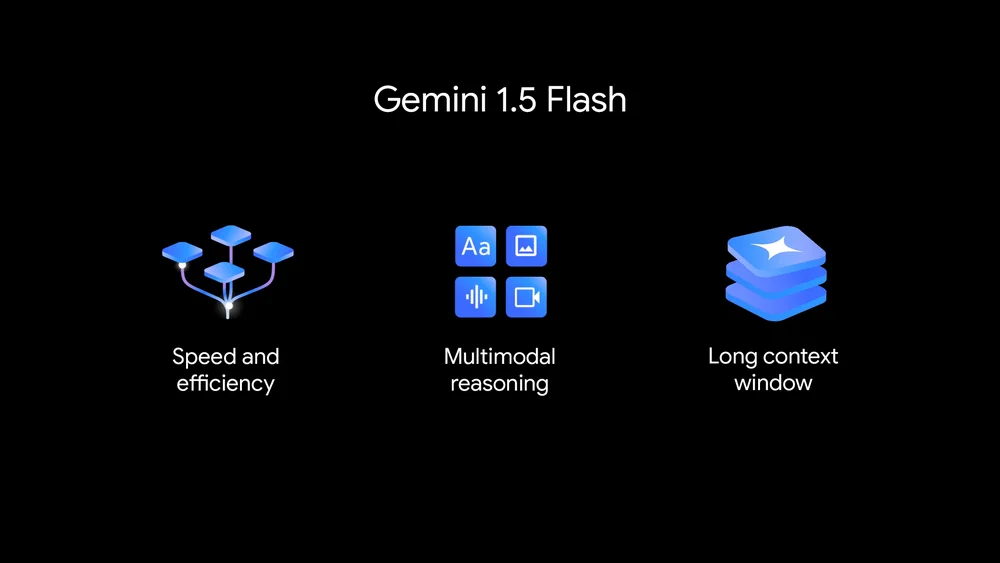
Gemini 1.5 Flash: Mô hình nhanh hơn và hiệu quả hơn
Gemini 1.5 Flash là mô hình mới nhất trong nhóm mô hình Gemini và là mô hình Gemini nhanh nhất hỗ trợ API. Gemini 1.5 Flash được tối ưu hóa cho các tác vụ vừa nặng, vừa nhiều trên quy mô lớn và có chi phí vận hành hợp lý hơn, cũng như sở hữu cửa sổ ngữ cảnh dài.
Theo ông Demis Hassabis, mặc dù đây là mô hình nhẹ hơn Gemini 1.5 Pro nhưng nó có khả năng cao trong lý luận đa phương thức với lượng thông tin khổng lồ và có chất lượng ấn tượng so với dung lượng của nó. Gemini 1.5 Flash vượt trội trong việc tóm tắt, trò chuyện, chú thích hình ảnh và video, trích xuất dữ liệu từ các tài liệu và bảng biểu dài, …. Gemini 1.5 Flash có được khả năng này là nhờ được Gemini 1.5 Pro đào tạo thông qua một quy trình được gọi là “chưng cất” (distillation), trong đó kiến thức và kỹ năng cần thiết nhất từ mô hình lớn hơn được chuyển sang mô hình nhỏ và hiệu quả hơn.
Bạn đọc có thể tham khảo thêm về Gemini 1.5 Flash trên trang công nghệ Gemini và tìm hiểu về tính khả dụng cũng như giá cả của 1.5 Flash.
Mô hình Gemini 1.5 Pro còn tốt hơn nữa
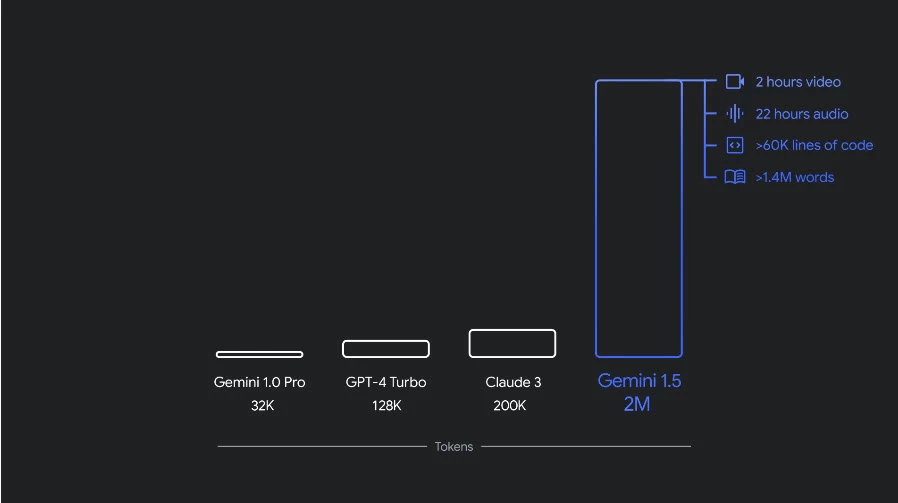
Độ dài ngữ cảnh.
Trong vài tháng qua, Google đã cải thiện đáng kể hiệu năng chung của mô hình tốt nhất là Gemini 1.5 Pro. Ngoài việc mở rộng cửa sổ ngữ cảnh lên 2 triệu token, họ còn nâng cao khả năng viết mã lập trình, lập kế hoạch và lập luận logic, khả năng đối đáp, cũng như khả năng hiểu âm thanh và hình ảnh thông qua các cải tiến về dữ liệu và thuật toán.
Ông Demis Hassabis cho biết: Mô hình Gemini 1.5 Pro có tiến bộ đáng kể về điểm benchmark, tức điểm hiệu năng trong một số lĩnh vực, như lý luận và viết mã lập trình, cũng như đạt điểm benchmark tốt nhất về phân tích hình ảnh và video, bao gồm: MMMU, AI2D, MathVista, ChartQA, DocVQA, InfographicVQA và EgoSchema.
Gemini 1.5 Pro giờ đây có thể làm theo các câu lệnh ngày càng phức tạp và nhiều sắc thái, bao gồm cả những mô tả ở cấp độ sản phẩm như vai trò, định dạng và kiểu dáng. Google đã cải thiện khả năng kiểm soát phản hồi của mô hình cho các trường hợp sử dụng cụ thể, chẳng hạn như mô phỏng phong cách phản hồi và cá tính của tổng đài viên hoặc tự động hóa quy trình công việc thông qua nhiều lệnh chức năng. Google đã cho phép người dùng điều khiển hành vi của mô hình bằng cách cài đặt hệ thống.
Google cũng đã bổ sung khả năng phân tích âm thanh trong API Gemini và Google AI Studio, vì vậy, mô hình Gemini 1.5 Pro hiện có thể xử lý hình ảnh và âm thanh cho các video được tải lên trong Google AI Studio.
Cập nhật cho Gemini Nano, mô hình xử lý tác vụ nội bộ trên thiết bị
Gemini Nano đang được mở rộng tính năng, ngoài việc xử lý văn bản thì nay còn bao gồm hình ảnh. Bắt đầu với Pixel, các ứng dụng sử dụng Gemini Nano với mô hình đa phương thức nay có thể tương tác thế giới theo cách thông thường, tức không chỉ thông qua văn bản mà còn thông qua hình ảnh, âm thanh và ngôn ngữ nói.
Bạn đọc có thể tìm hiểu thêm về Gemini 1.0 Nano on Android
Phiên bản mới của các mô hình mở (open model)
Ông Demis Hassabis nói rằng: “Hôm nay, chúng tôi cũng chia sẻ thông tin cập nhật về Gemma, mô hình mã nguồn mở của chúng tôi, vốn được xây dựng từ cùng nghiên cứu và công nghệ mà chúng tôi dùng để tạo ra mô hình Gemini.Chúng tôi xin giới thiệu Gemma 2.0, thế hệ mô hình mở tiếp theo của chúng tôi, hướng tới đổi mới AI có trách nhiệm (responsible AI innovation). Gemma 2.0 có kiến trúc mới được thiết kế để mang lại hiệu năng và hiệu quả đột phá, đồng thời sẽ có sẵn ở nhiều phiên bản.”
Nhóm mô hình Gemma đang mở rộng với PaliGemma, mô hình ngôn ngữ thị giác (vision-language model) đầu tiên của Google, lấy cảm hứng từ PaLI-3. Google đã nâng cấp Bộ công cụ AI tạo sinh có trách nhiệm (Responsible Generative AI Toolkit) với Bộ so sánh mô hình ngôn ngữ lớn LLM (LLM Comparator) để đánh giá chất lượng phản hồi của mô hình.
Tiến trình phát triển các tác nhân AI phổ quát (universal AI agents)
Ông Demis Hassabis nói rằng: “Là một phần trong sứ mệnh của Google DeepMind nhằm xây dựng AI một cách có trách nhiệm, nhằm mang lại lợi ích cho nhân loại, chúng tôi luôn muốn phát triển các tác nhân AI phổ quát hữu ích trong cuộc sống hằng ngày. Đó là lý do hôm nay chúng tôi chia sẻ Dự án Astra: thể hiện tầm nhìn của chúng tôi về tương lai của trợ lý AI.”
Theo ông Demis Hassabis, để trở nên thực sự hữu ích, một tác nhân (agent) cần hiểu và phản hồi với thế giới phức tạp và năng động giống như con người; đồng thời tiếp nhận và ghi nhớ những gì nó nhìn thấy và nghe thấy để hiểu bối cảnh và thực hiện hành động. Tác nhân cũng cần phải có tính chủ động, dễ huấn luyện và mang tính cá nhân để người dùng có thể nói chuyện một cách tự nhiên mà không bị gián đoạn.
Mặc dù Google đã đạt được tiến bộ đáng kinh ngạc khi phát triển các hệ thống AI có thể hiểu thông tin đa phương thức, nhưng việc giảm thời gian phản hồi cho nội dung hội thoại là một thách thức kỹ thuật khó khăn. Trong vài năm qua, Google đã nỗ lực cải thiện cách AI agent của mình nhận thức, suy luận và trò chuyện để người dùng có thể trò chuyện với nó một cách tự nhiên hơn và không có độ trễ hay bị lag trong hội thoại.
Các tác nhân này được xây dựng trên mô hình Gemini và các mô hình có nhiệm vụ cụ thể khác, đồng thời được thiết kế để xử lý thông tin nhanh hơn bằng cách mã hóa liên tục các khung hình video, kết hợp video đầu vào và giọng nói thành chuỗi sự kiện, đồng thời lưu thông tin này vào bộ nhớ đệm để truy xuất hiệu quả hơn.
Bằng cách tận dụng các mô hình thoại (speech models) hàng đầu của mình, Google cũng cải tiến cách chúng nói, mang lại nhiều ngữ điệu hơn. Những tác nhân này có thể hiểu rõ hơn về bối cảnh và phản hồi nhanh chóng trong cuộc trò chuyện.
Thật dễ dàng để hình dung ra một tương lai nơi bạn sở hữu một trợ lý chuyên gia bên mình, thông qua điện thoại hoặc mắt kính thông minh. Một số tính năng này sẽ có mặt trên các sản phẩm của Google, như ứng dụng Gemini, vào cuối năm nay.
Tiếp tục khám phá
Ông Demis Hassabis kết luận: “Cho đến nay, chúng tôi đã đạt được những tiến bộ đáng kinh ngạc với nhóm mô hình Gemini và chúng tôi luôn cố gắng phát triển công nghệ tiên tiến hơn nữa. Bằng cách đầu tư vào dây chuyền sản xuất đổi mới không ngừng, chúng tôi có thể tiên phong khám phá những ý tưởng mới, đồng thời mở rộng tiềm năng sử dụng của Gemini.”
Tham khảo: Gemini breaks new ground with a faster model, longer context, AI agents and more.
N.L.
Nguồn do Google cung cấp.
More from my site
 Apple có kế hoạch sử dụng phiên bản tùy chỉnh của Google Gemini cho Apple Intelligence
Apple có kế hoạch sử dụng phiên bản tùy chỉnh của Google Gemini cho Apple Intelligence Google I/O 2025: Các ứng dụng AI từ nghiên cứu đến hiện thực hóa giúp cải thiện cuộc sống
Google I/O 2025: Các ứng dụng AI từ nghiên cứu đến hiện thực hóa giúp cải thiện cuộc sống Google Workspace được tích hợp AI giúp mọi doanh nghiệp có thể sử dụng mô hình làm việc năng suất hơn
Google Workspace được tích hợp AI giúp mọi doanh nghiệp có thể sử dụng mô hình làm việc năng suất hơn Trường Đại học Fulbright Việt Nam được Google tài trợ 1,5 triệu USD để thúc đẩy nghiên cứu và giáo dục về AI tại Việt Nam
Trường Đại học Fulbright Việt Nam được Google tài trợ 1,5 triệu USD để thúc đẩy nghiên cứu và giáo dục về AI tại Việt Nam Google và NIC hợp tác trong sáng kiến trí tuệ nhân tạo “Kiến tạo Tương lai AI Việt Nam”
Google và NIC hợp tác trong sáng kiến trí tuệ nhân tạo “Kiến tạo Tương lai AI Việt Nam” Trải nghiệm AI mới trợ giúp nhà bán hàng trên Amazon quản lý kinh doanh theo thời gian thực
Trải nghiệm AI mới trợ giúp nhà bán hàng trên Amazon quản lý kinh doanh theo thời gian thực